페이징 처리시 자주 사용되는 Offset. 단순히 쿼리로 OFFSET을 수행하면 성능 저하가 일어난다.
offset 사용시 성능 저하 이슈에 대해 검토와 관련 글들
- http://devoluk.com/mysql-limit-offset-performance.html
- https://explainextended.com/2009/10/23/mysql-order-by-limit-performance-late-row-lookups/
- https://www.eversql.com/faster-pagination-in-mysql-why-order-by-with-limit-and-offset-is-slow/
이를 확인하기 위해 DB에서 직접 쿼리를 날려 보자 (속도 차가 나는 것은 실제 사용 쿼리보다 좀 더 단순한 쿼리로 비교했기 때문임) 30만건 이상의 데이터를 넣어둔 테이블에서의 결과임을 밝혀둔다.
1
2
3
SELECT * FROM 테이블
order by project_name asc
LIMIT 10 OFFSET 300000;
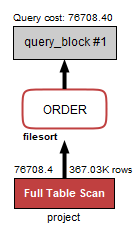
3.2초
Full Table Scan이 일어남 (전체 데이터 건수에 대한 접근)
그리고, 그 데이터들을 모두 정렬하는 과정의 코스트가 많이 발생함.
1
2
3
4
5
SELECT *
FROM 테이블 as p
JOIN (SELECT 키값
FROM 테이블
ORDER BY 정렬컬럼 LIMIT 300000, 10) AS t ON t.키 = p.키;
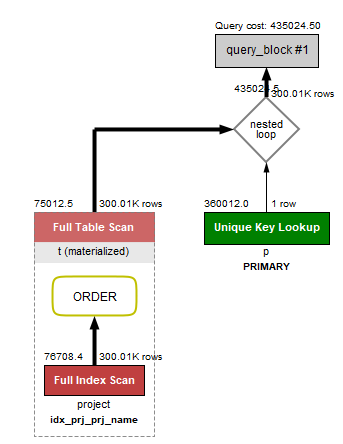
0.641초
Full Index Scan이 일어난 뒤, 인덱스를 정렬함.
정렬된 데이터를 기준으로 Unique Key Lookup 기반의 Nested Loop 처리로 인한 성능 향상
인덱스 구조 관련 팁
- LIMIT OFFSET 에서 사용하는 Sorting 값이 있다면, 해당 값을 Clustering Index로 잡으면 성능 이득을 더 크게 볼 수 있다.
- Sort 과정을 건너뛰어도 되는 만큼 처리할 데이터양이 많거나 클수록 차이가 나는 부분이니, 페이징할 데이터 양이 큰 경우 검토할 여지가 있다.