최근에 블로그 글이 뜸했는데, 이에는 여러가지 이유가 있었다.
첫번째로는 이직 후 적응도 하고 있었지만, 기본적으로는 Dev Toy를 많이 했다.
그 중 몇개를 운용해보고, 어느정도 버그가 잡힌 뒤에 Github 공개 프로젝트로 돌렸고, 이에 대한 얘기를 블로그에 써보고자 한다.
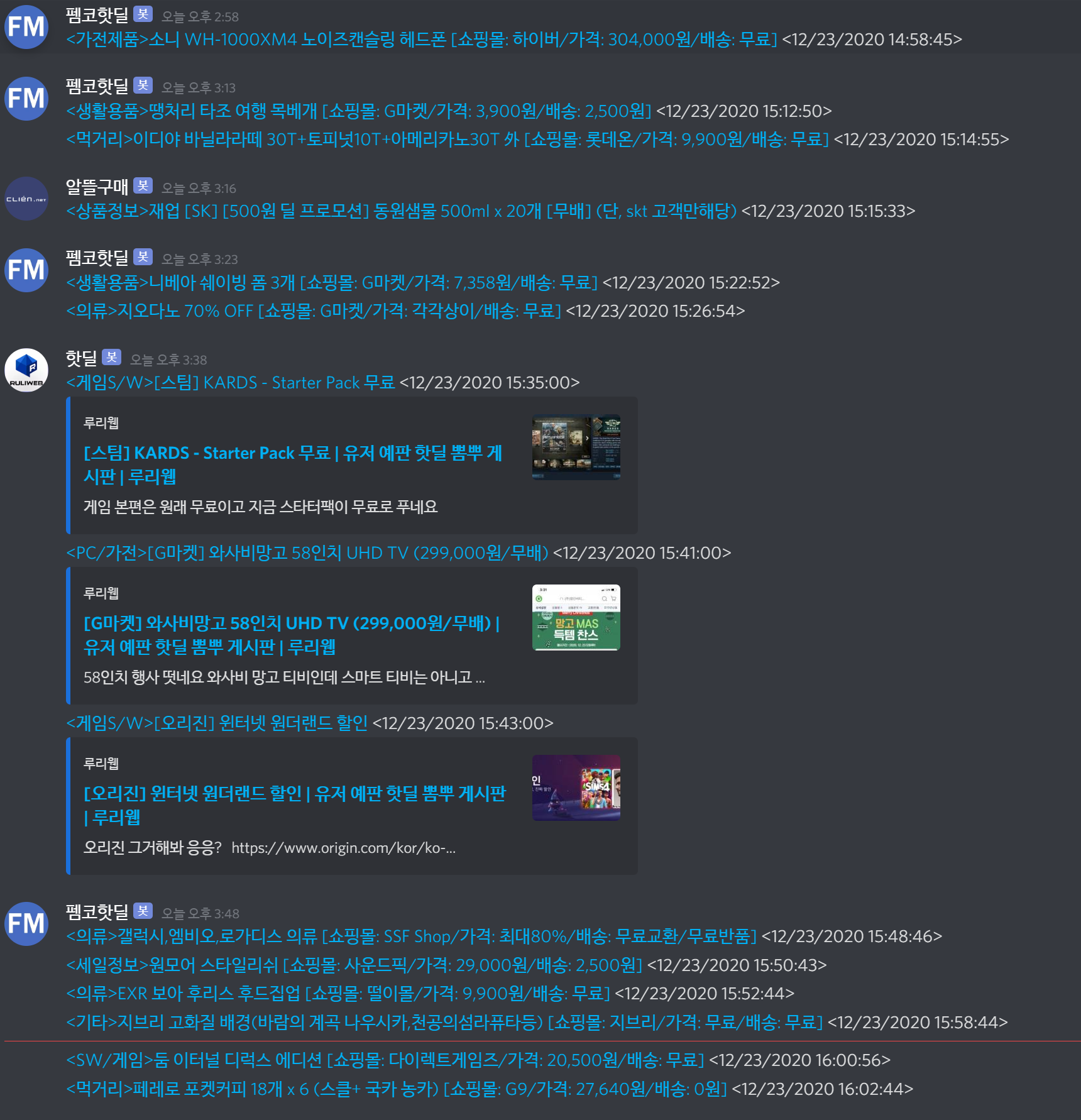
우선 내가 하루에 꽤 많은 시간을 쏟는 것이, News 찾아보기, 핫딜 게시판 보기였다.
가는 사이트, 열어보는 게시판이 여럿이다보니까 이 polling 만 해도 어마어마한 시간을 쏟게 됐다.
특히 hotdeal의 경우 놓치는 일이 많아서, 이를 극복(?)하고자 웹 크롤링을 시도하게 됐다.
처음에는 python을 썼었는데, python의 경우 디버깅이나 비동기 처리에 아쉬움이 있어, C# .NET CORE로 개발하게 됐다.
elky84/web-crawler: web-crawling (use Abot2), feed-crawling (use FeedReader)
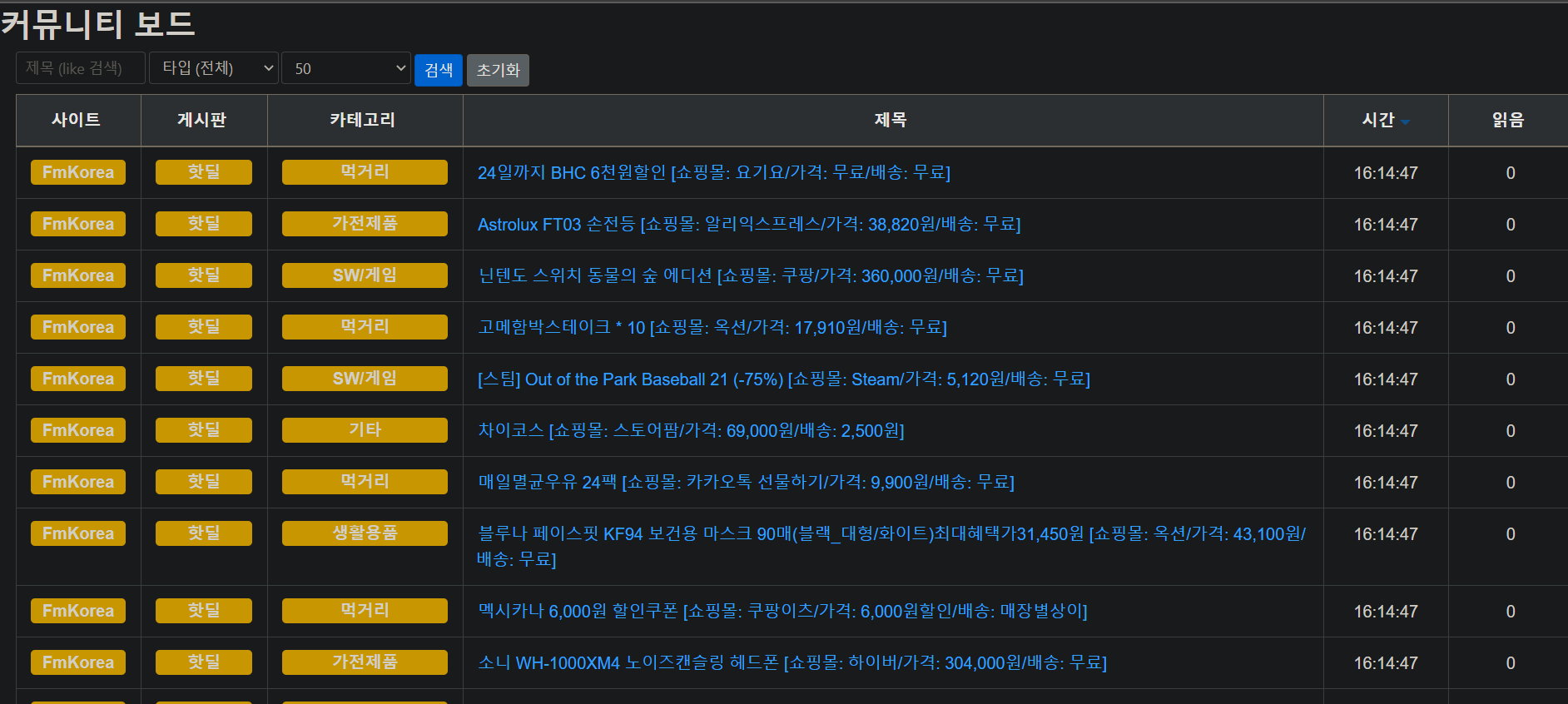
abot2라는 C# .NET CORE 기반의 크롤러를 이용했으며, 페이징 처리를 했다.
또한, Feedly를 통한 RSS구독을 해오긴했으나, 알림을 한 곳에 모아보고자하는 니즈가 있었는데, 이를 위해서 Feed (RSS) Crawling 기능도 포함하게 됐다.
나와 동일한 니즈가 있는 분들께 참고가 되거나, C# 기반 웹 크롤링에 관심있으신 분들께 도움이 되길 바래본다.