MongoDB를 실 운용해본 후기 및 상황에 따른 권장 구성에 대해서 설명해보고자 한다.
최종 데이터는 1.3TB였고, read & write node 역할을 함께 하게끔 구성해서 3대로 운용하다가, read node, write node 각각 3개씩으로 나누어 운용하며 겪었던 경험에 대한 이야기다.
1.3TB데이터는 모두 단일 콜렉션에 담았으며, 인덱스만으로 aggregation을 시도했고, 이 과정에서의 성능 차이를 주는 요소를 확인했으며, 일일 API 호출 통계(정상 API 호출까지 모두 집계)를 집계했으며, 일 데이터는 400MB~2GB 사이였다.
분산 콜렉션에 map reduce하는 방법도 고려해봄직 했으나, 이 역시 연산 코스트는 작지 않으며, 큰 단일 콜렉션에서의 성능과 이슈를 확인해보고 싶었다. (인덱스 효율, 인덱스를 타는 케이스, 타지 않는 케이스가 방대해진 인덱스에서도 동일하게 동작하는지 확인 등)
대다수의 상황에서는 hot data개념이라거나, read node, write node 분리 정도만 염두에 두어도 충분히 효과를 볼 수 있다.
MongoDB는 기본적으로 샤딩과 레플리카를 모두 기본 옵션으로 지원한다. 샤딩은 오토 샤딩을 지원하며, 이는 리밸런싱을 배제한 옵션이다.
MongoDB의 구성에서는 몇가지 이해하고 넘어가야 할 조건들이 존재한다. 아무리 RDB보다 빠르다지만 1억건 이상의 데이터에서는 결국 성능 문제를 맞닥뜨린다. 이 중 가장 큰 이슈가 되는 것은 당연하게도 agreegate 동작이다.
MongoDB는 기본적으로 memory mapped file을 기반으로 한다.
이는 메모리 + 가상 메모리를 이용한다는 의미로써, 물리 메모리가 적재할 데이터 보다 작다면 디스크 IO가 크게 발생하고 이는 곧 성능 저하로 이어진다는 의미다.
이 부분이 긴가 민가 했는데, 실제 운용해보니 인덱스에 있는 데이터는 메모리에 올리고 인덱스에 없는 데이터까지 연관 조회 혹은 aggregate시에 인덱스에 없는 데이터를 조건에 포함시켰을 때, 메모리에 없는 데이터를 읽기 위해 계속 메모리에 적재를 시도한다.
이 과정에서 가상 메모리를 결국 사용하게 되고 성능이 급격히 저하되는 것을 확인할 수 있었다.
또한 메모리에 올라와있는 데이터를 hot data라 부르는데, 이를 적절한 크기로 유지해주면 성능상 큰 이득을 볼 수 있다. hot data에 대한 자세한 이야기는 밑에서 좀 더 설명하겠다.
샤딩과 레플리카 구성 으로 넘어오자면, MongoDB의 경우 여타 db들과 비교했을 때 샤딩, 레플리카 구성 모두 쉽다.
MongoDB에는 3가지 종류의 서버가 존재한다.
MongoDB Sharding 구조
하나의 config 서버와 여러개의 MongoDB 서버로 구성되어 있다.
- Config 서버
- 중개자 계층, 샤딩을 위한 메타 데이터를 저장한다. (데이터들의 위치 정보를 저장)
- Mongos 서버
- MongoDB의 중개자 역할, Config 서버의 메타 데이터를 이용해 각 MongoDB에 데이터 접근을 도와준다.(라우터와 같은 역할)
- Mongod 서버
- MongoDB의 데이터 서버
- 서버 장애에 대비해 MongoDB 서버 안에 여러 개의 리플리카 셋 구조로 구성되어 있다.
Client(응용 계층) → Mongos(중계 계층) → Config(중계 계층) → Mongod(데이터 계층)
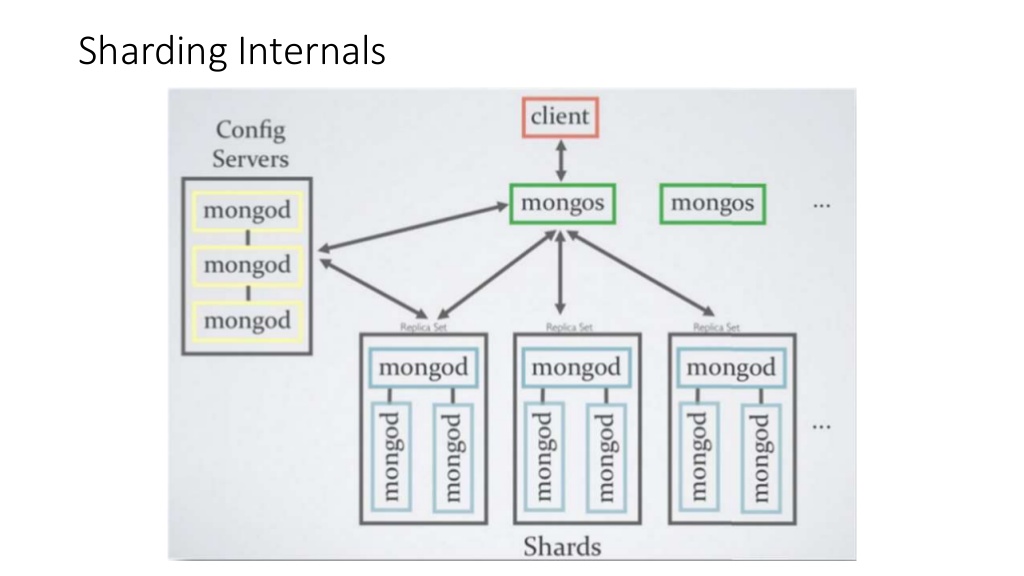
필요한 구성요소는 이렇고, 배치와 연관 관계 설정에 따라 여러가지 모델이 있을 수 있는데, 핵심은 read node와 write node(+read지만 write만 하는 것을 권장한다)를 잘 선정 해야 하는 데 있다.
read node와 write node를 같이 두지 않는 것은 RDB에서도 중요하나 MongoDB에서는 더욱 더 크게 중요하다.
위에서 언급한 hot data를 node마다 따로 보유하기 때문이다.
document를 참고해서 시스템을 구축하고 운용하면서 몇가지 궁금증이 생겼었다.
- config 서버는 왜 3대를 구축해야 하는가?
- config 서버는 registry+router라고 봐야 함.
- 결국 데이터를 쌓을 곳 혹은 읽을 곳을 전달해주는 서버가 되므로, 서버 수에 따라 안정성 및 반응 속도, 데이터 유실율, Read/Write 정합성을 맞추는 데에 중요한 역할을 한다.
- 3개의 서버중 하나가 죽어도 나머지 서버가 설정 정보를 보유,전달 하면서 지탱해주는 3중화라고 봐야 한다고 한다.
- 자동으로 해주는게 별로 없는데 auto sharding이라 부르는 이유는 무엇인가?
- https://nicewoong.github.io/development/2018/02/10/MongoDB-feature/를 포함한 몇몇 분들도 같은 의구심을 가지셨다.
- 내가 내린 결론은 기존 운용 중인 서비스의 재가동 없이 샤드를 추가할 수 있어서 auto sharding이라고 부른게 아닐까 싶다.
둘다 MongoDB 공식 페이지 및 각종 글을 읽어보고 내린 결론인데, 이견이나 보강하실 부분이 있으시다면 좀 더 자세히 설명해주시면 감사하겠다.
또 다른 팁은 무엇이 있을까?
aggregate처럼 집계연산은 실시간이면 좋긴하지만 또 일정 시간의 소요를 감안하고 운용되곤 한다. 실제로 hadoop 과 같은 빅데이터 솔루션들 대다수는 실시간이라기보다는 배치 잡으로 동작하여 긴 시간이 소요되는 걸 감내하고 운용되는 것을 감안하면 감내할 수 있는 부분이다.
- aggregate와 같은 메모리 사용량이 큰 동작을 처리하는 node를 분리하고, 응답성이 중요한 데이터를 다루는 read node를 분리하는 것도 하나의 전략이 될 수 있다.
- 메모리 사용량이 큰 동작은 hot data가 잦은 갱신이 이뤄지는 원흉이지만 또 한편으로는 통계나 집계의 핵심 역할이다. 이를 여타 솔루션으로 보내기보단, 직접 처리할 수 있으면 빅데이터의 중간 처리자나, 직접적인 통계 처리자의 역할을 충분히 수행 할 수 있기에, 여타 read node에 영향을 주지 않게끔 분리하는 것은 충분히 합리적인 선택지 중 하나가 될 것이다.
- document 단위로 최대한 read node를 분리해서, document 단위의 hot data를 의도하고 최대한 hot data 연산이 이루어 질 수 있게끔 구성하는 것도 방법이다.
- document가 유사하면, 유사한 쿼리를 요청할 확률이 높고 이는 같은 인덱스를 사용할 확률이 높다.
- 그럼에도 인덱스들이 메모리 사용량을 상회할 것이라고 생각된다면, 이 마저 감안해서 분산하는 것이 옳다.
- 특히 main db로써 사용중이라면 응답성의 핵심이 MongoDB의 응답 속도 일 것이므로, 인덱스를 얼마나 잘 활용할 수 있는지에 맞게끔 read node를 분산해야 한다.
- 여타 DB도 마찬가지이지만, mongo db도 항상 read & write node를 분리해야만 하는 것은 아니다.
- 내가 주로 사용한 agreegation 자체가 최근에 사용된 데이터 기반이 아닌, 전날 데이터 전체를 가져와야 했으므로, read node 자체가 write node가 바라보는 working set이 무의미한 구성이기도 했고, 서로 영향을 주고 받지 않게 하기 위해서였다.
- 대다수 상황에서는 read & write node는 일치 시키고, write node와 replica set 구축하는 것이 더 일반적이며, 효율적인 구성이 된다는 점을 염두에 두자.
너무나 중요해서 다시 한번 강조하자면, MongoDB를 구축한 서버의 메모리와 주로 다루게 되는 인덱스의 크기를 안넘어서게 하면 최대한 메모리 내에서의 연산을 이끌어내서 성능 저하를 피할 수 있다는 점이다.
node 분배의 최적화는 hot data를 RAM을 넘어서지 않게끔 관리해주고 hit rate를 높이는 데에 있으나, 이렇게 강조했음에도 현실적으론 용도에 맞게끔 node를 매번 구성하기 어렵다. auto-sharding이 된다고해도 리밸런싱이 지원되는 것은 아니며, 직접적으로 hot data (=working set) 를 관리하는 기능은 없기 때문.
node의 hot data(=working set)을 완벽히 최적화하긴 어렵기 때문에, 현실적인 가이드 라인은 active한 데이터가 MongoDB node의 물리 메모리 크기를 넘어서지 않게끔 어플리케이션을 구성하는 것 정도가 아닐까 싶다.
MongoDB도 rdb와 유사하게 쿼리 실행 계획을 볼 수 있다.
explain 명령을 통해 볼 수 있는데, 여기선 winningPlan, rejectPlan등의 성공과 실패시 어떻게 동작하냐만 보여줄 뿐 실제 어떤 쿼리가 인덱스를 잘 이용해서 Full Scan을 안할 것인지, hot data로 인해 가상 메모리를 크게 쓸 건지에 대한 설명까진 이어지지 않는다.
실은 나 역시 구축하고 두번의 구성 변경을 해야 했다. 이유는 예측한 데이터보다 훨씬 컸고, 용량이 크면 클수록 인덱스를 타지 않은 aggregate 동작은 시스템 부하가 컸으며, 물리 램 사용량이 매우 중요했고, 메모리에 존재하지 않는 데이터 억세스 코스트가 컸다.
node마다의 부하 분산도 첫 계획대로 되지 않았기 때문이다.
그럼에도 몇가지 팁은 최초 설계가 실제 운용시의 갭을 줄이는 데에 용이하지 않을까 생각한다.
내 시행 착오와 경험담이 도움이 되길 바란다.
참고
- https://nicewoong.github.io/development/2018/02/10/MongoDB-feature/
- http://sjh836.tistory.com/98
- https://dzone.com/articles/5-tips-to-optimize-MongoDB