이번에는 Netflix Zuul 도입기에 대해서 이야기 해보고자 한다.
지난 MSA 그리고 API Gateway 글을 읽고 오면 더 이해가 쉽게 될 것이다.
내가 합류했던 팀은 MSA로 구성되어 있었다.
반면 API Gateway가 존재하지 않았다 보니, frontend에 바로 물려 있는 서버에서 proxy 처리를 해주고 있었고, 그 서버에 interceptor를 통한 인증 로직도 함께 포함되어 있었다.
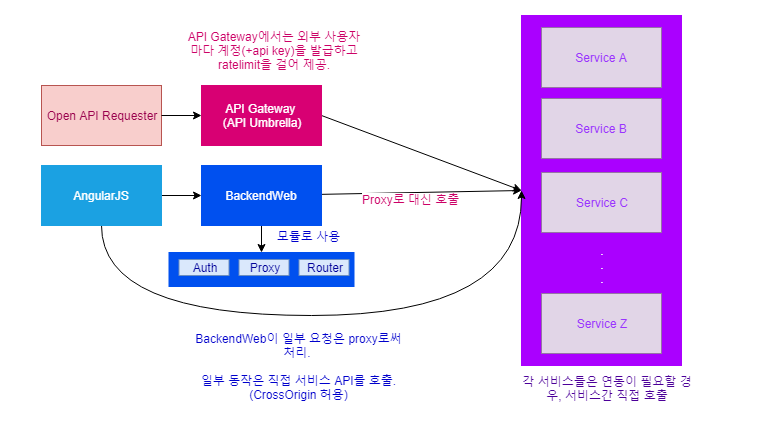
우선 frontend에서 proxy를 처리하는 코드가 범용적이지 않다보니, 이를 우회하기 위해서 javascript단에서 서비스를 직접 호출하는 상황이 일부 존재했다. 직접 호출시의 규격에 제약도 없다보니, 어떤 사용자가 호출한 것인지 분류해내기 매우 까다로울 수 밖에 없었다.
서비스별로 로드밸런싱/endpoint 변경 처리/부하 제어/호출 권한 관리 어느 하나 쉽지 않았다. 각 서비스가 어디에 떠있는지 관리하기 어렵기 때문에 호출 권한 검사, 부하 체크도 어려웠다.
각 서비스별 endpoint를 들고 있었어야 되는데, 내가 아닌 다른 서비스가 재시작 될 때에도 내가 들고 있는 값을 갱신해 주기 위한 여러가지 처리가 필요했다. (이는 동적 설정 파일 혹은 db에 관리하지 않은 이슈도 있긴하지만 endpoint 정보의 중복이란 관점만 생각해도 문제가 있다)
또한 frontend와 동일한 백엔드 서버를 거치자니 사용자 요청과 서비스에서의 호출인지 구분도 어렵고 모든 예외처리, 인증, 인가, 부하 제어, 로드밸런싱 로직이 서비스 갯수만큼 필요하다. 이를 sdk를 제공함으로써 조금은 편해질 수 있어도 기능의 역할의 중복은 피해갈 수 없다.
마찬가지로 Open API 제공 하기에도 어려웠는데, API 사용자별 ratelimt, 권한 검사, proxy (with router)를 구현해주고 관리해주어야 했기에 때문이다. 외부 사용 권한 제어는 API Umbrella를 통해서 대행하고 있었으나, frontend, 서비스간 호출까지 포함해서 일관성 있는 아키텍쳐를 구성하고 관리하고 싶은 니즈가 있었기에, 요구사항에 맞는 기술 선정을 위한 검토와 개발을 진행하게 되었다.
API Gateway가 도입 되는 과정에서 여러가지 도입 검토 후보군이 존재했다.
- ruby on rails : API Umbrella
- node.js : express gateway, proxy를 통한 자체 구현
- go : tyk
- lua : kong
- java : netflix zuul
최초에는 API Umbrella가 먼저 도입됐다. 다만 인증 인가 로직을 붙이기 위해서 rails 코드를 추가/관리해주어야 된다는 점과, 패키징 되서 배포되는 모델이다보니 코드 수정 및 연계가 불편한점으로 인해, 타 부서에 배포하는 용도로만 사용됐다.
이후 node.js로 proxy를 이용한 도입과 netflix zuul을 비교하게 되었는데, 이 중 zuul이 자바로 이루어진 점과 spring-cloud에 포함된 스프링 공식이되었고 spring 서버군에 적용될 공용 코드를 다수 이용할 수 있다는 점, 유틸리티 기능이 풍부하다는 점 등에서 선택하게됐다.
최근 여러 컨퍼런스나 블로그에서 언급된 내용이지만 나도 조금 설명을 하자면 zuul은 아래 4가지 핵심 기능으로 분류된다.
netflix zuul에 대해 간략히 살펴보자면 크게 4가지 기능으로 분류 된다.
- Zuul : Router and Filter
- Ribbon : Load Balancer
- Eureka : Registry Service
- Hystrix : Latency and fault tolerance
이렇게 네가지 기능을 통한 API Gateway 구현을 하게 된다.
이 중 zuul은 router를 통한 endpoint 관리와 filter를 통한 인증/인가 처리, 접근 제어, 부하 제어등을 구현하게 된다.
https://cloud.spring.io/spring-cloud-netflix/multi/multi__router_and_filter_zuul.html
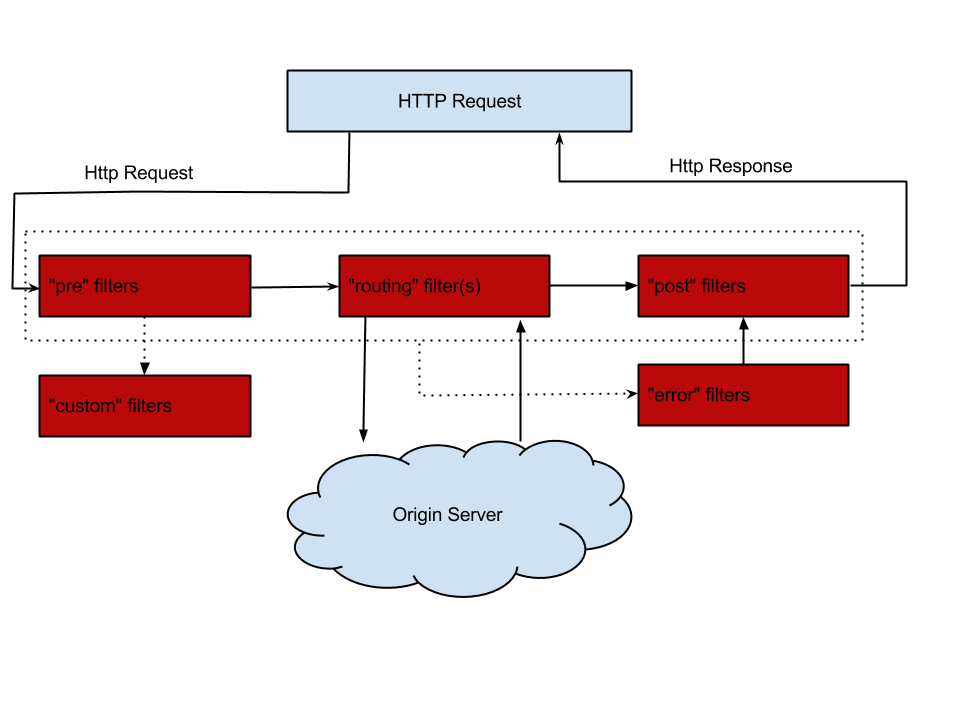
Filter의 종류와 각 Filter에서의 적절한 처리
- Pre
- Request Header 및 파라미터 검사. 일관성이 어긋난 요청을 하진 않는지. Ratelimit 처리. 요청자 정보를 얻어오기. 혹은 요청자 정보를 각 컴포넌트에 신뢰성 있게 전달. (헤더에 추가하는게 가장 좋다)
- Post
- Response Header 및 파라미터, Body 검사. Body 로깅도 처리하면 좋다. 처리 결과에 대한 로깅, Ratelimit을 위한 요청 기록 처리
- Error
- 오류 발생시 핸들링. 여기서 Exception을 catch해서 핸들링했다.
- Custom
- 무언가 부가 작업을 해주어야 할 때. (요청에 따라 다른 코드를 넣으면 좋다. 인증/인가라거나 기타 등등)
- Routing
- 어디로 라우팅할지를 결정 지어 줌. 이 시점에서 ribbon 사용시에는 ribbon에서 전달된 정보를 바탕으로 origin server를 결정짓는다.
- 만약 서버 목록 중 특정 서버로 보내고 싶은 로직을 구현하고 싶을 경우 이 곳에서 처리하면 된다.
zuul을 통한 service 관리를 간략히 살펴보면 다음과 같다.
zuul routes 예제 (application.yml)
1
2
3
4
5
6
7
8
zuul:
routes:
user_service: # serviceId
path: /users/** # users path 이하의 요청은 모두 아래 url로 route한다.
url: http://127.0.0.100
registry_service: # serviceId
path: /registry/** # registry path 이하의 요청은 모두 아래 url로 route한다.
url: http://127.0.0.101
해당 설정으로 구동 시킨 서버가 http://127.0.0.1이었다면,
- http://127.0.0.1/users/ 이하로 들어온 모든 request
- http://127.0.0.100 로 전달
- serviceId는 user_service
- http://127.0.0.1/registry/ 이하로 들어온 모든 request
- http://127.0.0.101
- serviceId는 registry_service
serviceId는 ribbon, eureka, hystrix등에서 설정 때 쓰이는 핵심 키 값이므로 유념하자.
위 예제는 zuul만 사용했기 때문에 정해진 경로로만 보낸다. 만약 load balancing을 하고 싶다면 아래와 같이 구성하면 된다.
https://spring.io/guides/gs/client-side-load-balancing/
1
2
3
4
5
6
users: # serviceId
ribbon:
eureka:
enabled: false
listOfServers: localhost:8090,localhost:9092,localhost:9999
ServerListRefreshInterval: 15000
serviceId로 들어온 요청을 listOfServers중 하나로 보낸다.
이 예시는 eureka를 사용하지 않는 케이스고 로드밸런싱 기능만 수행한다.
eureka 사용시 동작 구조는 다음과 같다.
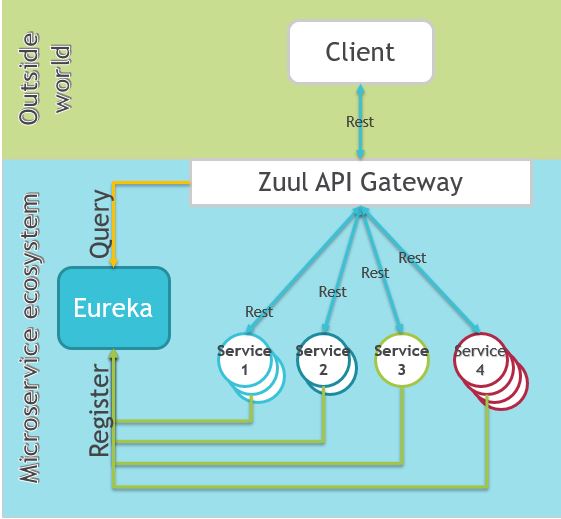
출처: https://exampledriven.wordpress.com/2016/07/06/spring-cloud-zuul-example/
아래 링크에도 잘 설명되어있으니 참고바란다. https://supawer0728.github.io/2018/03/11/Spring-Cloud-Ribbon%EA%B3%BC-Eureka/
hystrix의 경우 서비스 장애의 전파를 방지한다.
장애가 발생한 노드를 서비스 노드에서 제거하고, 요청에 대한 예외를 격리하여, 지연이 발생한 노드의 성능 저하가 다른 노드로 전파되지 않게끔 처리해준다.
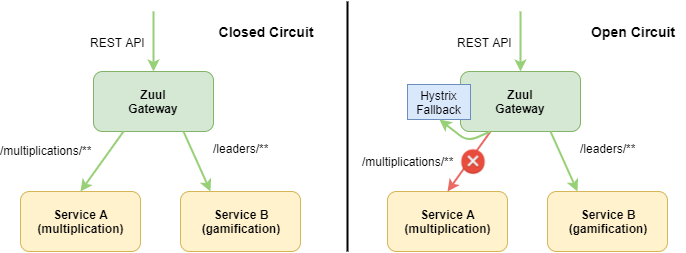
출처: https://thepracticaldeveloper.com/2017/06/27/hystrix-fallback-with-zuul-and-spring-boot/
fallback 처리를 서비스 구조에 맞게 처리해줌으로써, 장애 대응을 한다. 이에 대한 다양한 팁이 공유 되는데, 서비스 자체가 아니라 특정 node만 제거하게끔 연동한다거나, 미리 캐싱해둔 html을 내려줌으로써 최대한 유사하게 처리한다거나 하는 처리를 대비해두고, fallback 처리를 통해 번 시간을 실제 장애 대응에 맞게 대응하도록 가이딩한다.
자세한 내용은 아래 링크에서 자세히 설명해주셨다. https://supawer0728.github.io/2018/03/11/Spring-Cloud-Hystrix/
다시 돌아와 팀에서 구현한 내용은 zuul 위주로 사용하게 됐다. router를 통한 endpoint 집중 관리, filter를 통한 인증/인가/접근 제어/부하 제어가 가장 중요한 이슈였기 때문이었다.
이 과정에서 router를 서비스 별로 구분하려 했는데, 애초에 서비스를 기능 단위로 쪼개 놓은 상태여서 이부분은 endpoint 취합 및 API Gateway를 사용하게끔 가이딩 하는걸로 충분했다.
다만 API 사용자별로 과도한 API 호출이 이뤄지지 않게끔 제어하는 기능이 필요했는데, 이는 https://github.com/marcosbarbero/spring-cloud-zuul-ratelimit 를 사용자 단위로 처리할 수 있게 커스터마이징 해서 사용했다. 해당 모듈이 serviceId별로 ratelimit만을 제공해 커스터마이징이 불가피했다.
이어서 filter를 이용한 각종 처리를 검토했는데, 사용자를 3부류로 분류했다.
- Frontend
- 말 그대로 Web Frontend 호출.
- Frontend 사용자의 추가 인증을 처리한다.
- Service
- 기능별로 쪼개진 각 서비스.
- 다른 서비스를 호출하기 위해 분류한다.
- External (Open API Requester))
- 온전히 Service를 가져다가 사용하기만 하는 외부 사용자.
- 부하제어/인증/인가가 Service보다 조금 더 복잡해야 해서 따로 분류했다.
세가지 분류의 사용자는 각기 서버에서 미리 발급해둔 API-KEY를 사용하게 된다. API-KEY 자체는 JWT로 발급된 값으로써, 어떠한 사용자이며, 어떤 인증을 거쳐야하며, 어떤 ServiceId를 이용할 수 있는지를 담고 있다.
JWT를 이용한 이유는 JWT는 자체에 정보 값을 부여할 수 있어서 이를 이용하면 DB를 사용하지 않고도 각종 정보를 담을 수 있어서 였다. 단점은 기존에 발급된 토큰을 invalidate 시키기 어려운 점이다. 좀 더 자세한 내용은 다음 글에서 좀 더 자세히 다룰 예정이다.
이를 바탕으로 사용자 타입에 따른 인증 로직을 수행한다.
접근 제어의 경우에도 발급된 API-KEY에 따라 갈리는데, API-KEY별로 Ratelimit을 걸어서 일정 수준이상의 웹 콜을 요청 하지 못하도록 처리했다.
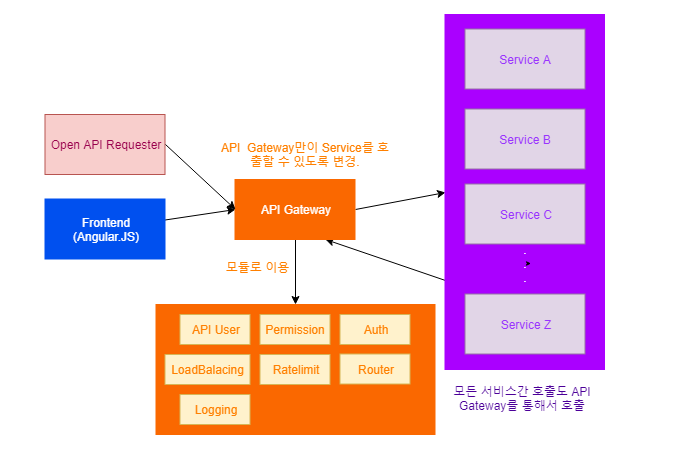
도입 이후 아키텍쳐는 다음과 같다.
웹 호출을 API Gateway로 모두 취합하고 나니 API 통계를 남길 수 있었다. 이전에는 통계를 남기기 위해 모든 API 서버마다 기록해야 했으며, 일부 에러는 취합되지 못하곤 했다. (서버가 꺼져서 응답이 없는 상황이나, interceptor 자체의 오동작 상황 등등)
이를 한 곳에 모을 수 있게 되자, 통계가 좀 더 확실해졌고 이 통계를 바탕으로 API 품질 개선을 이뤄 낼 수 있었다.
남기게 된 API 로그
- Request
- RequestPrefix
- RequestFullURI
- RequestParameters
- ipAddress
- Response
- ResponseActionLog
- ResponseStatusCode
- rtCode
- 식별 값
- tenant 단위 정보, 요청자 정보
- Error 발생시
- Error cause & message
- 기본 정보
- 시간
로그 서버 저장 및 통계는 MongoDB로 했는데, 이에 대한 이야기는 추후에 좀 더 자세히 다뤄보겠다.
결과적으로 netflix zuul이 대다수 작업을 해주었기 때문에, 일부 개선을 위한 동작에 대한 작업만으로 목표를 달성 할 수 있었다.
이와 동시에 Netflix zuul에 대해서 공부하면서, Filter, Interceptor, AOP의 차이도 알 수 있었다.
바퀴를 재발명 많이 해본 입장에서 (어쩔 수 없는 재발명도 있었다고 본다. 오픈소스로 잘 공개되지 않는 인하우스 라이브러리 기반 개발이 주였던 C++ 게임 개발의 전례 때문이기도 했으니 말이다.) 자바의 가져다 쓰는 환경. 그리고 잘 가져다 쓰는 것이 중요한 환경이란 것을 깨닳았기에 그 적절한 사례를 또 하나 찾고 적용한 것 같아 기뻤다.
물론 잘 만들어 공개해준 netflix에 매우 큰 감사를 표한다.