자료 구조란?
프로그램이 어떤 일을 할 때에는, 그 일을 하기 위해 필요한 데이터가 존재 합니다. 예를 들어, 비디오 대여점 관리 프로그램을 작성한다고 생각해 봅시다.
우선 비디오 정보들이 필요합니다. 비디오의 정보에는, 비디오에 담긴 미디어의 작품 명, 감독, 출연진 (혹은 성우) 등과, 비디오의 위치, 대여료, 대여기일 등의 정보를 포함합니다. 그리고, 회원 정보도 필요합니다. 회원 정보에는, 회원의 이름, 나이, 주소, 전화번호, 대여한 비디오 정보가 포함 될 것입니다. 이 정보들이 있어야만, 비디오 대여 관리를 프로그램으로 처리 할 수 있습니다.
이런 정보들을 어떻게 저장하고 관리 할까요? 그 저장하는 저장 데이터들이 바로 자료구조 (Data Structure) 입니다. 보통 자료구조와 함께 알고리즘 (Algorithm: 프로그래밍에서는 문제 해결을 위한 방법을 의미함)을 함께 다루는데요, 그 이유는 자료 구조에 따라서 효율적인 알고리즘이 각기 다르기 때문입니다.
자료구조가 엉터리로 짜여 있으면 쓸모 없는 데이터나, 중복된 데이터를 가지게 되고, 느린 데이터 처리, 오랜 처리 시간 등의 문제점을 발생시킵니다. 그렇게 되지 않기 위해, 이번 챕터에서는 좋은 자료구조를 만들기 위한 여러 가지에 대해 알아보도록 하겠습니다.
자료구조의 종류
가장 흔히 접할 수 있는 자료구조 중 하나는 배열입니다.
배열(Array)은 동일한 형태를 가지고, 메모리의 연속된 공간에 위치하는 데이터 집합을 의미하죠.
배열은 미리 크기만큼 선언 되어 있어야 하고, 중간에 데이터를 삭제 할 수 없으며, 데이터의 순서를 바꾸는 것도 힘듭니다. 아래 예제를 보시길 바랍니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
int main(int argc, char * argv[]) {
int number[10] = {
1,
2,
3,
4,
5,
6,
7,
8,
9,
10
}; // 배열 number의 초기 값으로 1~10을 차례대로 대입
number[5] = 0; //배열의 중간 위치에 있는 6번째 원소 (0부터 시작하기 때문에, [5]는 6번째 원소를 가리킵니다)의 값에 0을 대입
int temp = number[5]; //0이라는 수가, 삭제된 데이터라는 것을 의미하므로, number[5]에 저장된 값 0을 임시 변수 temp에 대입
for (int i = 6; i < 10; i++) //데이터가 삭제된 위치인 6번부터 하나씩 앞으로 당긴다
{
number[i - 1] = number[i];
}
number[9] = temp; // number[5]에 저장되어 있던 값을 저장해놓은 temp를 배열의 마지막 위치에 대입
}
위 코드는 배열 내에 원소를 삭제하는 코드 입니다.
배열에서 중간 위치의 데이터를 삭제하고, 그 공간을 채우는 일은 번거롭습니다. 여러 번의 연산이 필요하죠. 게다가 배열의 크기 자체는 그대로입니다. 이렇게, 크기의 변화가 불가능한 자료구조를, 정적 자료구조(Static Data Structure)라고 합니다.
또 다른 자료 구조로는, 리스트(Linked List : 링크드 리스트를 의미하고, 줄여서 리스트라고도 함)도 있습니다. 이 리스트도 마찬가지로 데이터 집합입니다만, 연속된 메모리 공간에 위치하지 않고, 자신의 앞에 위치한 데이터와 자신의 다음 데이터를 가리키는 포인터를 갖고 있습니다.
리스트는 자신의 다음에 위치한 데이터를 언제든지 바꿀 수 있습니다. 다음 데이터에 대한 정보를 포인터로 갖고 있기 때문이죠.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
struct Node {
Node * Next;
};
int main(int argc, char * argv[]) {
Node * Node1;
Node1 = (Node * ) malloc(sizeof(Node));
Node * Node2;
Node2 = (Node * ) malloc(sizeof(Node));
Node * Node3;
Node3 = (Node * ) malloc(sizeof(Node));
Node1 -> Next = Node2; //Node1의 다음 데이터는 Node2
Node2 -> Next = Node3; //Node2의 다음 데이터는 Node3
Node3 -> Next = NULL; //Node3가 마지막이다 (NULL)
free(Node2); //Node2가 삭제 되었다
Node1 -> Next = Node3; //이제 Node1의 다음 데이터는 Node3
}
위 예제를 보시면, Node 구조체는 자신의 다음에 올 데이터를 가리키는 포인터인 Next를 가지고 있습니다. 중간에 위치한 데이터였던 Node2가 삭제되었지만, Node2의 공백은 Node1의 다음 데이터로 Node3를 가리키게 하는 것만으로 쉽게 해결 됐습니다. 이처럼, 크기의 변화가 가능한 자료구조를 동적 자료구조(Dynamic Data Structure)라고 하죠.
정적 자료구조로는, 앞서 설명한 배열과, 레코드(Record)가 있습니다.
레코드(Record)는, 기본 단위로써 다뤄지는 데이터 묶음. C언어에서는 구조체나 공용체를 떠올리시면 됩니다.
동적 자료구조로는, 리스트(List), 스택(Stack), 큐(Queue), 덱(Deque)이 대표적입니다.
스택(Stack)은 후입선출(LIFO : Last In First Out)의 자료 구조로 서랍에 옷을 넣었다가 꺼낼 때를 떠올리시면 쉽습니다. 한번에 한 개씩만 물건을 꺼내야 한다면, 앞부분에 있는 나중에 들어간 옷들을 꺼내야만 먼저 들어간 옷을 꺼낼 수 있죠.
스택은 위에서 이야기했듯이 역 순서의 특성을 가집니다. 먼저 들어간 데이터가 나중에 처리 되고, 계산기의 내부 처리나, 연산장치에서 호출된 곳으로 되돌아가기 위해서 사용되곤 합니다.
큐(Queue)는 선입선출(FIFO : First In First Out)의 자료구조로, 버스를 기다리는 줄을 생각하시면 됩니다. 오랫동안 기다린 사람이 먼저 버스를 타게 됩니다. 새치기하는 사람이 없거나, 버스가 원래 정류장이 아닌 이상한 곳에서 정차해서 나중에 오는 사람을 태우는 특이한 상황이 아니라면 말이죠.
버스를 기다릴 때와 마찬가지로, 순서대로 데이터가 처리되어야 할 때 쓰입니다. 컴퓨터는 한번에 한가지 일 밖에 할 수 없기 때문에, 여러 개의 처리를 한꺼번에 요청 받는다면 한 개를 제외한 나머지 데이터는 나중에 처리해야 하는데, 그 순서를 정할 때 쓰이곤 하죠.
덱(Deque)은 양방향에서 입/출력 가능한 자료구조로, 스택이나 큐가 사용될 수 있는 모든 상황에서 사용할 수 있습니다. 덱은 양방향 입/출력이 가능하지만, 입/출력에 제한을 건 특수한 덱 들도 있습니다. 한 방향에서만 입력이 가능한 덱을 스크롤(Scroll)이라고 부르고, 한 방향에서만 출력이 가능한 덱을 셸프(Shelf)라고 부릅니다.
지금까지 자료구조에 대해서 간략하게 알아보았고, 이제부터는 자료구조들이 어떻게 사용되는지, 어떤 장단점을 갖고 있는지 살펴보도록 하겠습니다.
검색 알고리즘
검색(Search)이란 말 그대로, 무언가를 찾는 것을 말합니다. 무엇을 찾을까요? 지나간 첫사랑? 내 돈 떼먹고 도망간 친구? 초등학교 동창? 보통 오랜만에 연락처를 잊어버린 친구를 다시 찾을 때 어떤 방법을 사용하시나요?
1
2
3
4
1. 다른 친구에게 물어본다.
2. 다 모임, 아이러브스쿨, 싸이 월드 등에서 찾아본다.
3. 졸업 앨범의 연락처를 뒤져본다.
4. 전국 전화번호부를 펴놓고 하나씩 전화해서 물어본다.
친구를 찾기 위한 여러 가지 방법들을 모두 검색이라 부를 수 있습니다. (무식한 4번 방법까지도 말이죠)
졸업 앨범의 연락처에는 반 단위로 나뉘어져 있으며, 가나다 순으로 정렬이 되어있어 찾기 쉽습니다. 싸이 월드의 경우, 년도와 성별, 이름으로 찾습니다. 임의대로 오라클, SQL같은 데이터베이스를 쓰지 않는다고 가정하겠습니다. 각 년도 마다 남녀로 데이터를 나눠두고, 가나다 순 정렬을 해놓으면, 수천만 명의 데이터를 처음부터 하나씩 검색하는 것에 비해 매우 효율적으로 데이터를 찾을 수 있습니다.
여러 가지 검색 방법 중 먼저 비효율적인 검색으로 알려져 있음에도 널리 쓰이는 검색인, 순차검색(Sequence Search)에 대해 알아보겠습니다. 순차검색은 처음 데이터부터 차례대로 하나씩 찾는 검색 방법입니다.
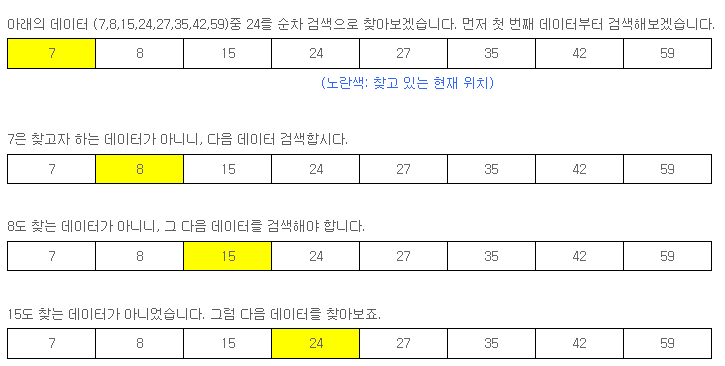
찾았습니다. 4번째 데이터가 찾고자 하는 데이터인 24였군요. 이 경우는, 데이터가 앞쪽에 위치해서 4번 만에 찾을 수 있었지만, 찾고자 하는 데이터가 59였거나, 존재하지 않는다면 데이터를 모두 검색하고 나서야 결과를 알 수 있기 때문에 비효율적입니다.
아래 코드는, 배열내의 원소를 정해진 크기만큼 순차검색하며, 키 값이 배열 내에 존재하는지 검사합니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
int SequenceSearch(int * ar, unsigned int size, int key) {
unsigned int i;
for (i = 0; i < size; i++) {
if (ar[i] == key) {
return i;
}
return -1;
}
}
int main(int argc, char * argv[]) {
int ar[] = {
25,
11,
43,
71,
38,
33,
59,
21,
56,
22,
45,
75,
64,
59,
93,
112,
159,
124,
163,
9
};
unsigned int size = sizeof(ar) / sizeof(int);
int key;
scanf("%d", & key);
int result = SequenceSearch(ar, size, key);
if (result == -1)
printf("찾으시는 키 값을 배열 내에서 찾을 수 없었습니다");
else
printf("배열 내에서 %d번째에 존재하는 값을 찾았습니다. %d", result);
}
순차 검색은 사실 단점이 많은 검색 방법이지만 정렬이 되지 않은 데이터에도 사용할 수 있다는 장점도 있습니다. 그리고 사용하기도 편해서 많이 쓰이는 검색 방법이죠.
자주 쓰이는 다른 검색으로는, 이진검색(Binary Search)도 있습니다. 이진 검색은 대소 비교를 통해 데이터를 찾는 범위를 반씩 줄여가며 찾는 방식을 말합니다.
주의 할 점은, 이진 검색을 하기 위해서 검색 전에 반드시 데이터가 오름차순 정렬(Sort)되어 있어야만, 제대로 된 결과를 얻을 수 있다는 점입니다. (사실, 이진 검색만이 아니라 순차검색을 제외한 대부분의 검색이 정렬을 필요로 합니다)
이진 검색 시에는 유효한 범위의 최소값 + 최대값 / 2. 즉, 중간 값에서부터 대소 비교를 하며 범위를 좁혀 원하는 값을 찾습니다.
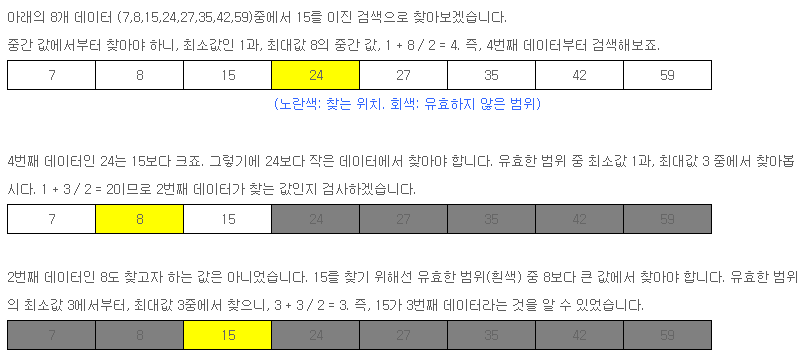
아래 코드는, 이진 검색을 통해 입력 받은 수를 찾는 코드입니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
int BinarySearch(int * ar, unsigned int size, int key) {
unsigned int half_value;
unsigned int lower_value = 0;
unsigned int upper_value = size - 1;
while (1) {
half_value = (lower_value + upper_value) / 2;
if (ar[half_value] == key)
return half_value;
else if (ar[half_value] < key)
lower_value = half_value;
else
upper_value = half_value;
if (lower_value == upper_value - 1)
return -1;
}
}
int main(int argc, char * argv[]) {
int ar[] = {
5,
8,
15,
28,
32,
45,
48,
52,
69,
71,
85,
94,
103,
112,
118,
124,
125,
138,
143,
157
};
unsigned int size = sizeof(ar) / sizeof(int);
int key;
scanf("%d", & key);
int result = BinarySearch(ar, size, key);
if (result == -1)
printf("찾으시는 키 값을 배열 내에서 찾을 수 없었습니다");
else
printf("배열 내에서 %d번째에 존재하는 값을 찾았습니다. %d", result);
}
순차 검색이 가장 마지막에 데이터를 찾게 될 수도 있는데 비해, 20개의 데이터가 있을 때 최대 5번 검색만으로 데이터를 찾을 수 있을 정도로 매우 효율적입니다.
순차검색보다 이진검색이 훨씬 빠르니까, 이진검색만 쓰면 된다고 생각하실 분도 있으실 겁니다만, 이진 검색의 경우 정렬되어 있어하는 것만이 아니라, 배열처럼 임의 접근 가능한 자료구조에서만 사용할 수 있다는 점도 생각하셔야 합니다.
검색은 데이터를 단순히 찾는 것에서 의미를 두는 것이 아니라, 빨리 찾는 것에 의미가 있습니다. 이진 검색은 반드시 정렬되어야 하기 때문에 데이터를 정렬하는 시간이, 검색 시간에 포함되어 있는 것과 마찬가지라서, 검색 방법만이 아니라, 정렬 방법도 매우 중요합니다. 그래서 검색을 위한 선행 조건인 정렬에 대해 알아보도록 하겠습니다.
정렬 알고리즘
정렬에는 작은 것부터 큰 것으로 정렬하는 오름차순(Ascending)과, 큰 것부터 작은 순서로 정렬하는 내림차순(Descending)이 있습니다. 정렬이라는 말 자체가, 특정 기준에 맞춰 데이터를 나열한다는 의미인데, 그 기준에 따라 오름 차순, 내림 차순 정렬을 하는 것입니다. 레코드들을 기준 값(Key)끼리 대소비교를 통해 순서를 바꿔주는 과정을 정렬이라고 부르죠.
간단한 정렬 방식 중 하나인, 버블 정렬(Bubble Sort)을 먼저 알아보겠습니다.
버블 정렬은, 현재 데이터가 바로 다음 데이터가 작은지 (오름차순일 때. 내림차순의 경우 큰지를 비교해야 함) 비교해서 위치 바꿈을 반복해가며 정렬하는 방법을 말합니다.
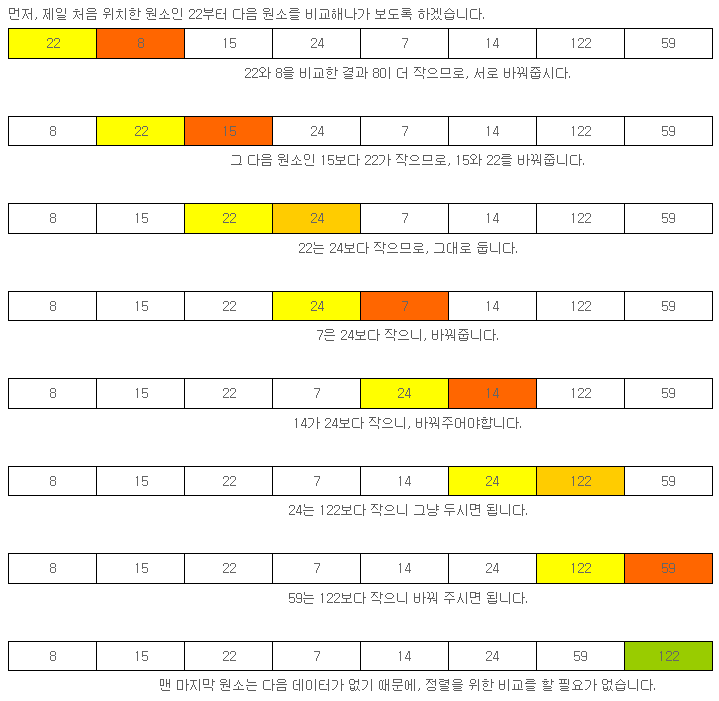
이렇게 정렬하고 나면, 마지막 원소인 122는 정렬되어있는 것이기 때문에, 검사할 필요가 없어집니다. 그러므로, 다음 정렬 시도 시에는 59와, 122는 비교하지 않아도 됩니다.
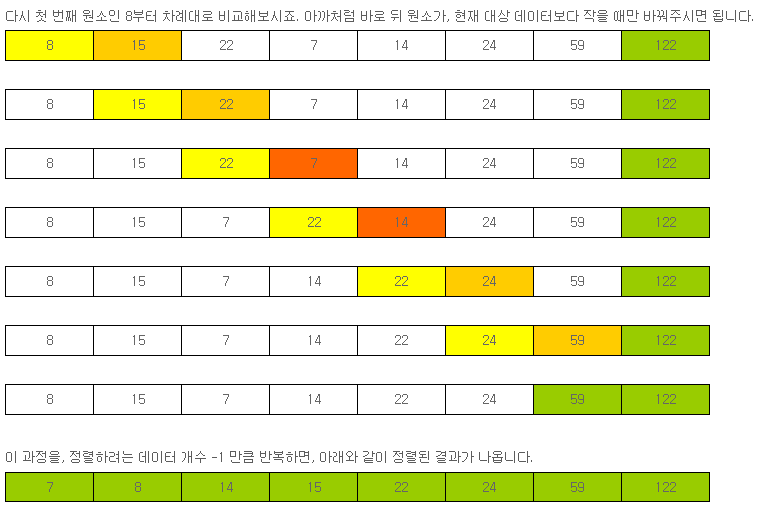
쉽게 사용할 수 있는 또 다른 정렬로는 선택 정렬(Selection Sort)이 있습니다.
선택 정렬이란, 자신의 다음에 위치한 원소들 중, 최소값 (오름차순의 경우. 내림차순일 때는 최대값)을 찾아서 자신과 위치 바꿈을 반복하면 됩니다.
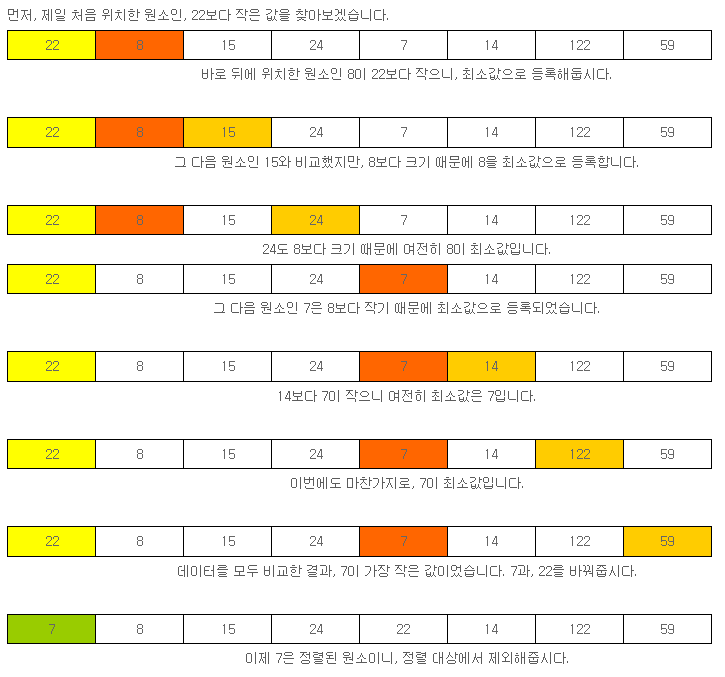
먼저, 제일 처음 위치한 원소인, 22보다 작은 값을 찾아보겠습니다.
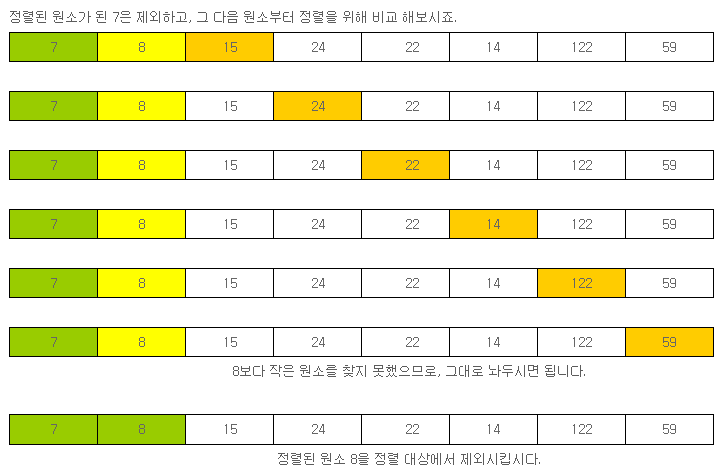
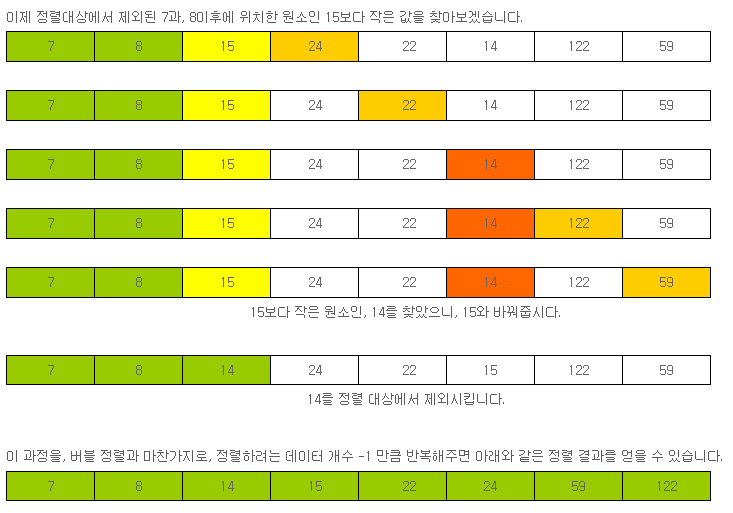
이제 정렬대상에서 제외된 7과, 8이후에 위치한 원소인 15보다 작은 값을 찾아보겠습니다.
이번에는 또 다른 정렬 방법인 삽입 정렬 (Insertion Sort)에 대해서 알아보겠습니다.
삽입 정렬이란, 정렬할 키 값을 임의의 장소에 저장해 두었다가, 왼쪽 데이터와 차례대로 비교해가며 자신보다 큰 데이터는 뒤로 보내는 방식으로 정렬합니다. 삽입 정렬은 현재 데이터의 왼쪽 데이터와 비교하기 때문에, 첫 번째 데이터가 아닌, 두 번째 데이터부터 정렬을 시작합니다.


삽입 정렬도 버블 정렬, 선택 정렬과 마찬가지로, 두 번 루프를 돌지만, 새로운 데이터가 들어왔을 때, 루프 한번만으로도 정렬 완료 할 수 있는 등 여러 가지 장점이 있죠. 실제로, 삽입 정렬의 단점을 보완한 여러 정렬 (쉘 정렬 등) 방법이 있고, 사용되고 있죠.
일반적으로 많이 사용되는 범용적인 정렬 중에 가장 빠른 정렬로는, 퀵 정렬 (Quick Sort)이 있습니다.
퀵 정렬은 전체 데이터를 기준 값을 경계로, 그 값보다 큰 값, 작은 값들의 두 개의 블록으로 나누고, 그 분할된 블록들을 같은 방법으로 반복해서 정렬하는 방법을 사용합니다.
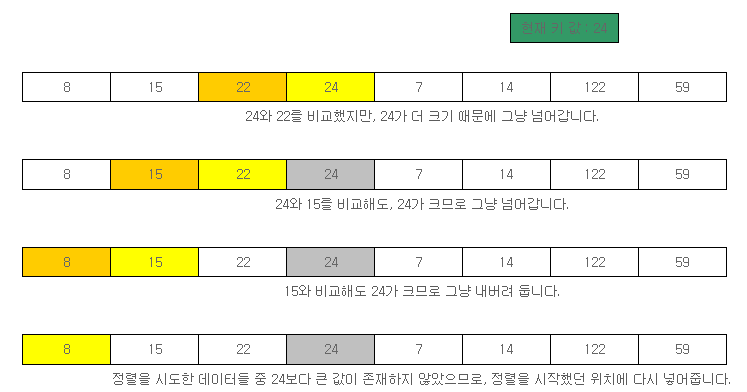
퀵 정렬을 하기 위해서, 배열의 첫 번째 값인 22를 기준 값으로 잡고 정렬을 시도해보겠습니다. 먼저, 왼쪽 끝에서부터 22보다 작은 값을 찾고, 오른쪽 끝에서부터 22보다 큰 값들을 찾고, 기준 값보다 크고 작은 각각의 값을 찾았을 때, 서로 값을 바꿔줍니다. 찾는 위치가 겹쳐지면 정렬을 종료하고 다음 원소를 정렬하면 됩니다.

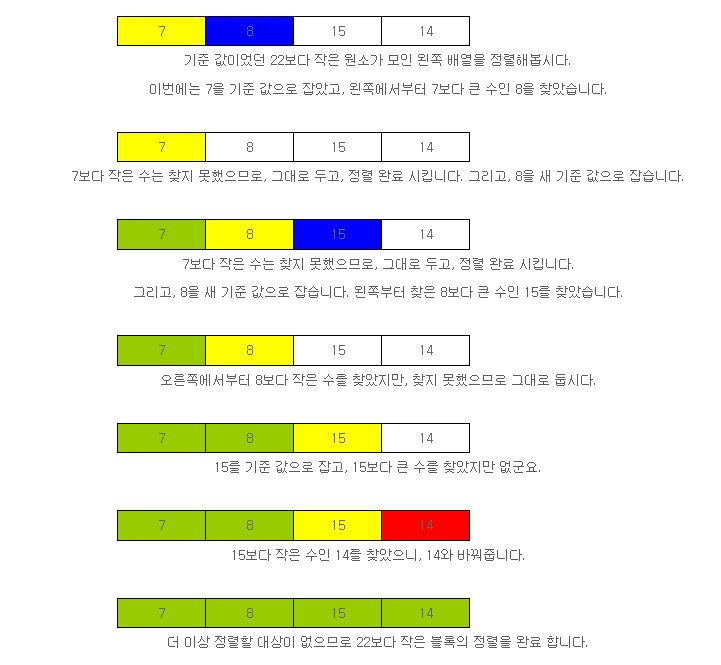
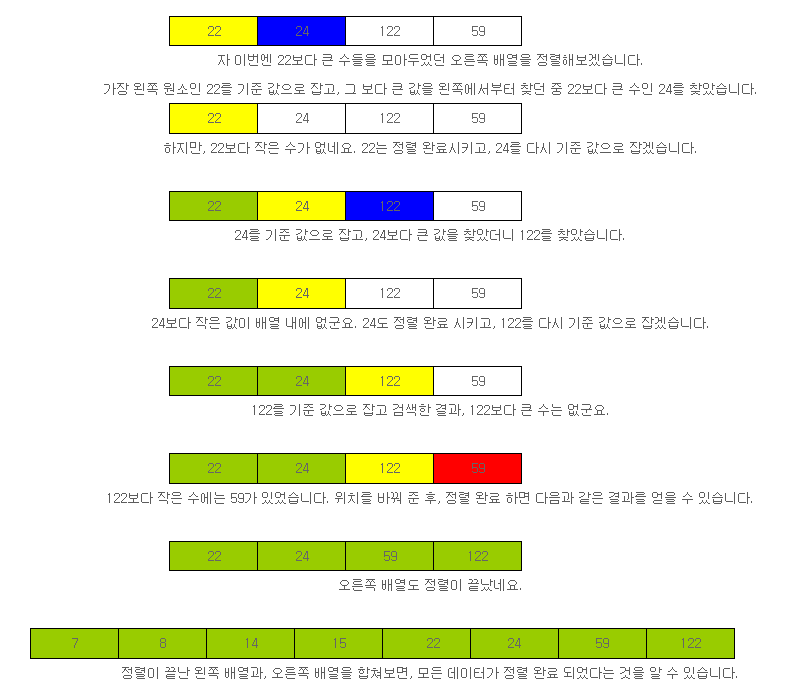
퀵 정렬은 기본적으로 데이터를 빠르게 정렬할 수 있지만, 정렬해야 할 데이터가 적은 경우에는 버블 정렬이나, 선택 정렬 등 루프를 두 번 순회하는 알고리즘과 큰 차이를 보여주진 못합니다.
어떤 상황에서나 퀵 정렬이 가장 빠르게 동작하는 알고리즘은 절대 아니며, 가장 좋은 정렬 알고리즘은 더더욱 아닙니다. 퀵 정렬은 기본적으로 다른 정렬보다 뛰어난 성능을 보여주지만, 역순으로 정렬되어있는 경우 (예를 들면, 오름차순으로 정렬해야 할 때 현재 데이터가 9, 8, 7, 6, 5.. 인 경우)에는 그다지 성능이 좋지 않습니다.
상황에 따라서는, 좋지 않은 효율을 보여주는 버블 정렬이 좋은 선택일 때도 많습니다. 200개 미만의 데이터를 정렬해야 하는 상황이고, 그 코드가 매우 적게 호출 된다면 굳이 퀵 정렬을 사용할 필요는 없습니다. (물론, 조금이라도 더 빠르게 하고 싶으신 마음은 이해합니다만, 대부분의 상황에서 그 정도 차이는 사실 중요하지 않습니다.)
여기서 설명한 알고리즘들은 일반적으로 널리 알려졌고, 많이 사용되는 알고리즘들일 뿐입니다. 최적의 알고리즘은 여러 가지 주변 상황을 모두 염두에 두고 생각해야만 찾을 수 있는 것이기 때문에, 알고리즘의 장/단점을 잘 이해하고, 상황에 맞게 응용하도록 노력 해야 할 것입니다.